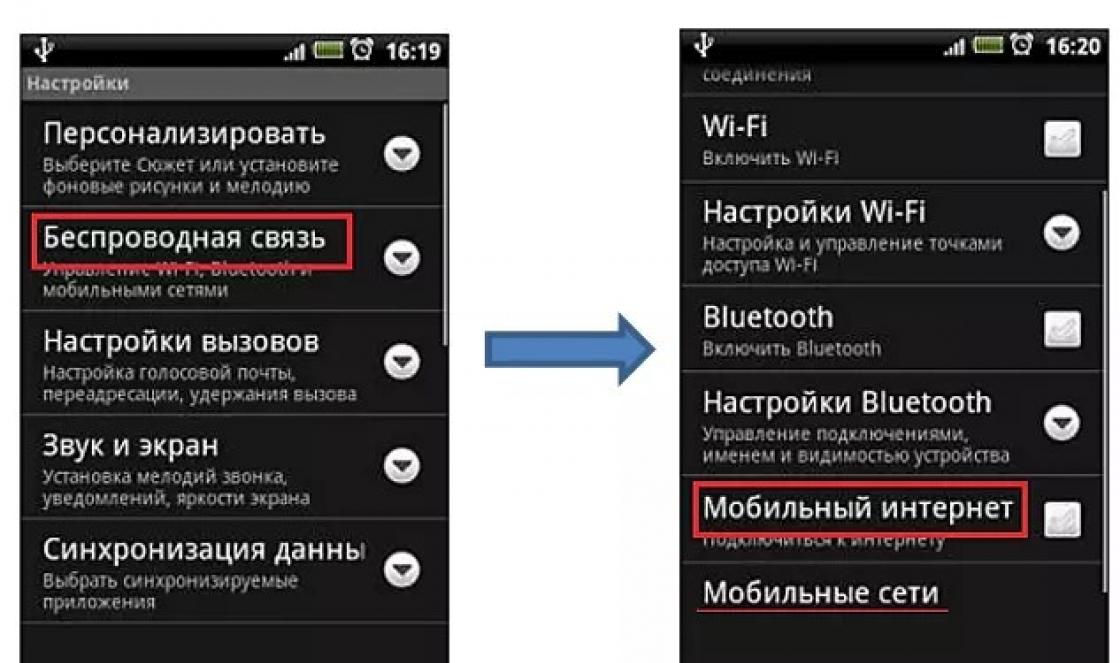
Отрасль PLM развивается уже более десяти лет и наступил тот момент, когда предприятия, опробовав решения, выбранные изначально, вполне резонно решают сменить существующую PLM на другую, либо существенно изменить конфигурацию текущей. И тут возникает вопрос миграции данных PLM из старой системы в новую. Как мы знаем, даже трансляция самих геометрических данных является непростой и неоднозначно решаемой задачей, миграция данных PLM – еще более сложный и пока малоизвестный процесс.
Как это бывает
Выбор новой системы PLM был сделан, команда руководителей с облегчением празднует результат сложных усилий этого выбора. На деле, только теперь начинается настоящая работа, планирование и осуществление миграции данных из существующих систем в новую целевую платформу PLM. Существующие данные компании содержат значительную часть интеллектуальной собственности (ИС) и, следовательно, конкурентные преимущества и капитал компании. Успех внедрения новой системы в значительной степени зависит от выполнения эффективной миграции существующих данных, интеллигентно, качественно и своевременно.Этот сценарий регулярно повторяется в том или ином виде по всему миру и в любой отрасли. С быстрыми темпами совершенствования технологий, усилением конкурентного давления, приводит к тому, что многие компании постоянно оценивают их PLM-решения и проводят улучшения. Решение может быть вызвано признанием того, что текущее решение, или, чаще, его техническое обслуживание, либо использование нескольких систем, не устраивают руководство компании. Кроме того, есть еще один общий мотив - последствия приобретений компании и осознание того, что консолидация их различных PLM решений является оправданным. Еще один сценарий – необходимость массивной перенастройки текущей платформы. Независимо от причин изменений, эффективное выполнение изменений будет зависеть от успешной миграции существующих данных на новую платформу.
Проблемы миграции данных
Миграция данных выносит на первый план многочисленные вопросы. Например, может выясниться, что это первая за многие годы ревизия того, как компания выбирала средства управления данными о продукте. Для того чтобы преодолеть очевидные недостатки в текущей модели данных, которая развивалась с течением времени, компании, возможно, придется изменить части модели или расширить ее. В любом случае, эти изменения окажут дополнительное давление на процесс перехода от старого к новому, простой перенос данных может оказаться невозможным. Один из важнейших моментов миграции заключается в том, что сначала нужно определить все данные, которые подлежат рассмотрению. Многие считают, что речь идет лишь о передаче цифровых данных, однако опытные специалисты наверняка признают, что какая-то часть критической ИС компании может все еще быть в печатном виде, либо вообще ее носителями являются головы ведущих сотрудников.После того как данные, которые подлежат миграции были идентифицированы, необходимо разработать и исполнить процессы проверки их правильности. Часто данные могут оказаться устаревшими, поскольку последние изменения не были внесены в более ранние версии данных. Кроме того, часто используются дублированные данные (или поддерживается в нескольких системах), требуя постоянной или периодической проверки согласованности и чистки данных. Определение полного объема данных для миграции требует использования знаний наиболее опытных сотрудников компании.
Возможно, одной из самых больших проблем миграции данных являются сроки миграции. Старые данные будут постоянно пополняться и модифицироваться, так как компания не может остановить свою работу и ждать завершения новой реализации PLM. Кроме того, в реальности коллектив, осуществляющий миграцию, имеет весьма ограниченные технические сроки для реального переключения, типично это - выходные или праздничные дни. Необходимость уложиться в доступное календарное время требует реализации алгоритмов миграции с помощью специальных инструментов, так как данные могут легко содержать в себе сотни тысяч (или даже миллионов) записей.
Пример решения
Обратимся к опыту тех, кто осуществлял и осуществляет миграцию данных PLM на регулярной основе. Одним из признанных специалистов в области миграции данных PLM является немецкая компания PRION Group , имеющая одиннадцатилетний опыт оказания таких услуг и эффективный инструментарий для их выполнения. Так как портфолио PRION включает в себя интерфейсы для наиболее распространенных PDM и унаследованными системами, из которого данные должны быть перенесены, в каждом конкретном случае у компании нет необходимости заново разработать ПО для миграции. Это позволяет быстро разработать план перехода с учетом особенностей конкретной компании и быстро выполнить миграцию, чтобы минимизировать ее воздействие на развитие продукта и производства. На рисунке ниже изображена схема типового процесса миграции данных по методологии PRION.Наиболее существенно то, что работоспособность этой схема многократно подтверждена выполненными проектами миграции данных PLM у многочисленных клиентов PRION. Более того, неоднократные попытки произвести прямую трансляцию данных из одной системы PLM в другую доказали 100% неработоспособность такого примитивного подхода. Среди факторов, определяющих такое положение дел: сбор данных из нескольких источников, необходимость преобразования и чистки данных, их аттестации и загрузки в новую систему (ы), которые также могут быть физически распределены. Таким образом, существуют совершенно неприемлемые при переходе на новую платформу PLM.
Для снижения этих рисков, PRION разработал средства миграции, которые используют промежуточную базу данных. Данные экспортируются в промежуточную базу данных и, перед загрузкой в новую целевую платформу PLM, преобразуются в этой базе данных. Такой подход не приводит к немедленному изменению в рабочих данных и бизнес может продолжаться как обычно, в то время как разрабатываются правила и детали процесса миграции данных. Критическим фактором для успеха миграции является создание системы управления изменениями, чтобы не только отслеживать изменения, сделанные в ходе миграции самих данных, но и изменения данных, сделанные после загрузки в новую платформу PLM. Эта система управления изменениями должна поддерживать конкретные требования заказчика от самого процесса миграции до запуска новой системы в эксплуатацию в реальных условиях.
Тот факт, что PRION может использовать многие из сценариев миграции из своей обширной библиотеки, которая была разработана для бывших клиентов снижает риски миграции и снижает затраты для будущих клиентов значительно. Этот подход помогает во многих трудных сценариев миграции, особенно когда целевая система является распределенным решением.
Для получения более детальной информации об инструментах и услугах PRION рекомендую обратиться на сайт
Перенос данных - это перемещение хранимой цифровой информации между компьютерами, системами или форматами. Перенос данных происходит по ряду причин, включая замену или обслуживание сервера, изменение центров обработки данных, проекты консолидации данных и обновление системы. Так как большая часть корпоративных знаний и бизнес-аналитики компании содержится в ее данных, любой проект миграции данных должен быть тщательно выполнен, чтобы минимизировать риски.
РАЗГРУЗКА «Миграция данных»
Перенос данных представляет собой значительный риск непрерывности бизнеса, если он выполнен неправильно. Потеря данных, конечно, является худшим сценарием, но компании также должны иметь дело со временем простоя, проблемами совместимости и общей проблемой производительности системы. Перенос данных затрудняется из-за большого количества данных, различных форматов данных и различий в данных в корпорациях.
Чтобы свести к минимуму риски миграции данных, компании создают подробные политики переноса данных, которые по мере необходимости приостанавливают резервное копирование, порядок перемещения и параллельные среды данных. Если компания не может запускать среду предварительной миграции при подготовке новой среды, тогда будет значительное время простоя, так как бизнес-операции над текущими приложениями приостанавливаются, чтобы разрешить миграцию данных. Этот тип переноса остановки, переноса и запуска может потребоваться при переходе на новые платформы или при наличии жестких ограничений на физическое хранение, а для существующей технологии хранения требуются свопы или исправления.
Миграция данных с нулевым временем простоя
Модель миграции с нулевым временем простоя зависит от наличия достаточного количества хранилища для создания и запуска двух полных сред. Полная копия данных компании берется в новую среду и проверяется, пока сотрудники остаются в старой среде. Ошибки разрабатываются из новой системы, гарантируя, что все приложения все еще работают, и все там, где должно быть. По завершении тестирования появляется новая копия, и все сотрудники переходят на новую среду. Старая среда данных иногда остается открытой в течение нескольких месяцев, чтобы сотрудники могли получать файлы из старой системы данных, но не записывали новые данные на эти серверы. Во всех миграциях данных выполняется проверка данных после миграции для проверки потери данных.
Одна вещь, которая может улучшить миграцию данных, заключается в очистке и стандартизации практики данных до миграции. Организация данных компании часто является отражением различных привычек в подаче своих людей. Два человека с одинаковой ролью могут использовать совершенно разные методы. Например, сохранение контрактов по поставщику в одном случае, а также в течение финансового года и месяца в другом. Унификация методов данных может быть гораздо более важной задачей, чем фактическая миграция данных, но чистые, когерентно организованные данные, подкрепленные четкими политиками, помогают будущим доказательствам данных компании для многих миграций еще впереди.
 Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (, , и др.), так и в Интернете (преимущественно, англоязычном).
Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (, , и др.), так и в Интернете (преимущественно, англоязычном).
В первом разделе этой статьи я рассматриваю основные проблемы, которые возникают в командах программистов при внесении любых изменений в структуру базы данных. Во втором разделе я попытался выделить основные общие подходы к тому, в каком виде изменения структуры базы данных можно хранить и поддерживать в процессе разработки.
Терминология
База данных - совокупность всех объектов БД (таблиц, процедур, триггеров и т.д.), статических данных (неизменяемых данных, хранящихся в lookup-таблицах) и пользовательских данных (которые изменяются в процессе работы с приложением).Структура базы данных - совокупность всех объектов БД и статических данных. Пользовательские данные в понятие структуры БД не входят.
Версия базы данных - определенное состояние структуры базы данных. Обычно у версии есть номер, связанный с номером версии приложения.
Миграция , в данном контексте, - обновление структуры базы данных от одной версии до другой (обычно более новой).
В этом смысле термин миграция, похоже, используется во многих источниках (особенно этому поспособствовали миграции из gem"а Active Record, входящего в состав Ruby on Rails). Однако при использовании этого термина возникает двусмысленность: человек, который не знает контекста, скорее подумает, что речь идет о переносе базы данных с одной СУБД на другую (MySQL => Oracle), а то и вовсе о миграции процессов/данных между нодами кластера. Поэтому предлагаю в случаях, когда контекст неочевиден, использовать более точный термин: версионная миграция баз данных.
Зачем это нужно?
Разработчики, которые уже сталкивались с проблемой рассинхронизации версий БД и приложения, могут пропустить этот раздел. Здесь я напомню, почему нужно соблюдать паритет версий приложения и базы данных и какая общая проблема при этом возникает.Версия базы данных должна соответствовать версии приложения
Итак, представьте себе следующую ситуацию: команда из нескольких программистов разрабатывает приложение, которое активно использует базу данных. Время от времени приложение поставляется в продакшн - например, это веб-сайт, который деплоится на веб-сервер.Любому программисту в процессе написания кода приложения может понадобиться изменить структуру базы данных, а также, сами данные, которые в ней хранятся. Приведу простой пример: допустим, есть необнуляемое (not nullable) строковое поле в одной из таблиц. В этом поле не всегда есть данные, и в этом случае там хранится пустая строка. В какой-то момент вы решили, что хранить пустые строки - семантически неправильно в некоторых случаях (см. , ), а правильно - хранить NULL"ы. Для того, чтобы это реализовать, понадобятся следующие действия:
1. Изменить тип поля на nullable:
ALTER myTable CHANGE COLUMN myField myField VARCHAR (255) NULL DEFAULT NULL ;
2. Так как в этой таблице на продакшн БД уже наверняка есть пустые строки, вы принимаете волевое решение и трактуете их как отсутствие информации. Следовательно, нужно будет заменить их на NULL:
UPDATE myTable SET myField = NULL WHERE myField = "" ;
3. Изменить код приложения так, чтобы при получении из БД данных, хранящихся в этом поле, он адекватно реагировал на NULL"ы. Записывать в это поле тоже теперь нужно NULL"ы вместо пустых строк.
Из пункта 3 можно видеть, что приложение и база данных - неразрывные части одного целого. Это означает, что при поставке новой версии приложения в продакшн, нужно обязательно обновлять и версию базы данных, иначе приложение попросту не сможет правильно работать. В данном примере, если до новой версии будет обновлено только приложение, то в какой-то момент произойдет вставка NULL в необнуляемое поле, а это очевидная ошибка.
Таким образом, обновление версии приложения требует корректной версионной миграции базы данных .
Так ли это просто?
Осознав, что паритет версий БД и приложения необходим, вам нужно удостовериться, что миграции БД до нужной версии всегда будут выполняться правильно. Но в чём здесь проблема? Ведь, на первый взгляд, сложного здесь ничего нет!Тут снова обратимся к живому примеру. Допустим, программисты в процессе разработки записывают свои изменения структуры и данных БД в отдельный файл в виде SQL-запросов (как DDL -, так и DML -запросов). А при каждом деплое последней версии приложения вы одновременно обновляете до последней версии и базу данных, выполняя запросы из того самого SQL-файла… Но погодите, с какой версии
вы обновляете БД до последней версии? «С прошлой»? Но так ли хорошо вы помните, что конкретно из себя представляла прошлая версия (её выпустили 2 месяца назад)? Если нет, то как вы собрались её обновлять? Ведь без точной информации о состоянии структуры и данных выполнить корректную миграцию невозможно: если вы непредумышленно выполните запросы, которые уже когда-то выполнялись, это может привести к потере данных или нарушению их целостности.
Простой пример - замена паролей на их MD5-суммы. Если повторно выполнить такой запрос, то данные можно будет восстановить только из бэкапа. Да и вообще, любые UPDATE "ы, DELETE "ы, и даже INSERT "ы, выполненные повторно, могут привести к крайне нежелательным последствиям. Не говоря уже о несвоевременных TRUNCATE "ах и DROP "ах (хотя такие случаи намного менее вероятны).
Кстати говоря, с этой точки зрения, недовыполнить - не меньшая опасность для работоспособности приложения, чем перевыполнить.
Таким образом, можно сделать вывод, что в процессе версионной миграции все запросы должны выполняться только один раз и, к тому же, в правильной последовательности . Последовательность важна потому, что одни изменения могут зависеть от других (как в примере с обнуляемым полем).
Общие принципы версионной миграции
В предыдущем разделе мы выделили важные критерии, которые показывают, что же требуется от процесса версионной миграции. Это:- единоразовое выполнение каждого изменения (SQL-запроса);
- строго предустановленный порядок изменений.
- чтобы любую версию базы данных можно было обновить до любой (обычно, самой последней) версии;
- чтобы набор SQL-запросов, реализующих миграцию между любыми двумя версиями, можно было получить как можно быстрее и проще;
- чтобы всегда можно было создать с нуля базу данных со структурой самой последней версии. Это очень полезно как в процессе разработки и тестирования, так и при развертывании нового продакшн-сервера;
- чтобы, в случае работы над разными ветками, при последующем их слиянии ручное редактирование файлов БД было сведено к минимуму;
- чтобы откатить БД на более раннюю версию было так же просто, как и обновить на более новую.
Основание миграции
Как оказалось, у большинства подходов есть общий принцип: им необходимо основание (baseline) - некоторое эталонное состояние БД, от которого можно отталкиваться. Эта концепция довольно хорошо описана в статье «Versioning Databases – The Baseline» Скотта Аллена.Попросту говоря, основание - это дамп структуры базы данных для версии, которая принята за базовую. Имея на руках основание , впоследствии всегда можно будет создать БД с нуля. После применения к этой БД всех миграций, созданных в процессе разработки, получим БД со структурой самой последней версии.
Метод инкрементных изменений
Этот метод хорошо описан в статье «Versioning Databases – Change Scripts» все того же Скотта Аллена. Схожий подход также описан в статье «Managing SQL scripts and continuous integration» Майкла Бэйлона.Структура файлов
Пример того, как в этом случае может выглядеть папка с файлами-миграциями:Database
|- Baseline.sql
|- 0001.03 .01.sql
|- 0002.03 .01.sql
|- 0003.03 .01.sql
|- 0004.03 .02.sql
|- 0005.03 .02.sql
|- 0006.03 .02.sql
"- 0007.03 .02.sql
В этом примере в папке хранятся все файлы, созданные при разработке версии 03 . Впрочем, папка может быть и общей для всех версий приложения.
В любом случае, самый первый файл, который появится в такой папке, - основание (Baseline.sql). После этого любое изменение в БД сабмиттится в репозиторий в виде нового файла-миграции с именем вида [номер файла].[версия].[подверсия].sql .
Фактически, в этом примере в имени файла содержится полный номер версии БД. То есть после выполнения файла-миграции с именем 0006 .03.02.sql база данных обновится с состояния, соответствующего версии 03.02.0005 , до версии 03.02.0006 .
Хранение истории версий
Следующий шаг - добавление в базу данных специальной таблицы, в которой будет храниться история всех изменений в базе данных.CREATE TABLE MigrationHistory
Id INT ,
MajorVersion VARCHAR (2),
MinorVersion VARCHAR (2),
FileNumber VARCHAR (4),
Comment VARCHAR (255),
DateApplied DATETIME ,PRIMARY KEY (Id)
)
Это всего лишь пример того, как может выглядеть таблица. При необходимости, её можно как упростить, так и дополнить.
В файле Baseline.sql в эту таблицу нужно будет добавить первую запись:
INSERT INTO
MigrationHistory (MajorVersion, MinorVersion, FileNumber, Comment, DateApplied)
VALUES ("03" , "01" , "0000" , "Baseline" , NOW())
После выполнения каждого файла-миграции в эту таблицу будет заноситься запись со всеми данными о миграции.
Текущую версию БД можно будет получить из записи с максимальной датой.
Автоматическое выполнение миграций
Завершающий штрих в этом подходе - программа/скрипт, который будет обновлять БД с текущей версии до последней.Выполнять миграцию БД автоматически довольно просто, т.к. номер последней выполненной миграции можно получить из таблицы MigrationHistory, а после этого остается только применить все файлы с бо́льшими номерами. Сортировать файлы можно по номеру, поэтому с порядком выполнения миграций проблем не будет.
На такой скрипт также возлагается задача добавления записей о выполненных миграциях в таблицу MigrationHistory.
В качестве дополнительных удобств, такой скрипт может уметь создавать текущую версию БД с нуля, сначала накатывая на БД основание , а затем выполняя стандартную операцию по миграции до последней версии.
Плюсы, минусы, выводы
Быстрое и удобное выполнение миграции до последней версии;Механизм нумерации версий. Номер текущей версии хранится прямо в БД;
Для максимального удобства нужны средства автоматизации выполнения миграций;
Неудобно добавлять комментарии к структуре БД. Если их добавлять в Baseline.sql, то в следующей версии они пропадут, т.к. основание будет сгенерировано с нуля вновь, в качестве дампа новой версии структуры. Вдобавок, такие комментарии будут быстро устаревать;
Возникают проблемы в процессе параллельной разработки в нескольких ветках репозитория. Так как нумерация файлов-миграций - последовательная, то под одинаковыми номерами в разных ветках могут возникнуть файлы с разными DDL-/DML-запросами. Как следствие, при слиянии веток придется либо вручную редактировать файлы и их последовательность, либо же в новой, «слитой» ветке начинать с нового Baseline.sql, учитывающего изменения из обеих веток.
Этот метод в различных формах довольно широко распространен. К тому же, он легко поддается упрощению и модификации под нужды проекта.
В интернете можно найти готовые варианты скриптов по инкрементному выполнению миграций и встроить в свой проект.
Метод идемпотентных изменений
Этот метод описан в статье «Bulletproof Sql Change Scripts Using INFORMATION_SCHEMA Views» Фила Хэка. Описание схожего подхода также изложено в ответе на этот вопрос на StackOverflow.Под идемпотентностью понимается свойство объекта оставаться неизменным при повторной попытке его изменить.
В тему вспоминается смешная сцена из «Друзей»:)
Основная идея этого подхода - написание миграционных файлов таким образом, чтобы их можно было выполнить на базе данных больше одного раза. При первой попытке выполнить любую из SQL-команд, изменения будут применены; при всех последующих попытках ничего не произойдет.
Эту идею проще всего уяснить на примере. Допустим, вам нужно добавить в БД новую таблицу. Если вы хотите, чтобы в том случае, если она уже существует, при выполнении запроса не возникло ошибки, - в MySQL для этих целей есть краткий синтаксис:
CREATE TABLE IF NOT EXISTS myTable
id INT (10) NOT NULL ,
PRIMARY KEY (id)
);
Благодаря ключевой фразе IF NOT EXISTS , MySQL попытается создать таблицу только в том случае, если таблицы с таким именем еще не существует. Однако такой синтаксис доступен не во всех СУБД; к тому же, даже в MySQL его можно использовать не для всех команд. Поэтому рассмотрим более универсальный способ:
IF NOT EXISTS
SELECT *
FROM information_schema.tables
WHERE table_name = "myTable"
AND table_schema = "myDb"
THEN
CREATE TABLE myTable
id INT (10) NOT NULL ,
myField VARCHAR (255) NULL ,
PRIMARY KEY (id)
);
END IF ;
В последнем примере роль параметра условного выражения играет запрос, который проверяет, существует ли таблица myTable в базе данных с именем myDb . И только в том случае, если таблица отсутствует, произойдет, собственно, ее создание. Таким образом, приведенный запрос является идемпотентным.
Стоит отметить, что в MySQL по какой-то причине запрещено выполнять DDL -запросы внутри условных выражений. Но этот запрет легко обойти - достаточно включить все подобные запросы в тело хранимой процедуры:
DELIMITER $$CREATE PROCEDURE sp_tmp() BEGIN
IF NOT EXISTS
--
-- Условие.
--
THEN
--
-- Запрос, изменяющий структуру БД.
--
END IF ;END ;
$$CALL sp_tmp();
DROP PROCEDURE sp_tmp;
Что за птица такая - information_schema?
Полную информацию о структуре базы данных можно получить из специальных системных таблиц, находящихся в базе данных с именем information_schema . Эта база данных и ее таблицы - часть стандарта SQL-92, поэтому этот способ можно использовать на любой из современных СУБД. В предыдущем примере используется таблица information_schema.tables , в которой хранятся данные о всех таблицах. Подобным образом можно проверять существование и метаданные полей таблиц, хранимых процедур, триггеров, схем, и, фактически, любых других объектов структуры базы данных.Полный перечень таблиц с подробной информацией об их предназначении можно посмотреть в тексте стандарта . Краткий перечень можно увидеть в уже упоминавшейся выше статье Фила Хэка . Но самый простой способ, конечно же, - просто открыть эту базу данных на любом рабочем сервере БД и посмотреть, как она устроена.
Пример использования
Итак, вы знаете, как создавать идемпотентные SQL-запросы. Теперь рассмотрим, как этот подход можно использовать на практике.Пример того, как в этом случае может выглядеть папка с sql-файлами:
Database
|- 3.01
| |- Baseline.sql
| "- Changes.sql
"- 3.02
|- Baseline.sql
"- Changes.sql
В этом примере для каждой минорной версии базы данных создается отдельная папка. При создании каждой новой папки генерируется основание и записывается в Baseline.sql. Затем в процессе разработки в файл Changes.sql записываются все необходимые изменения в виде идемпотентных запросов.
Предположим, в процессе разработки в разное время программистам понадобились следующие изменения в БД:
a) создать таблицу myTable;
b) добавить в нее поле newfield;
c) добавить в таблицу myTable какие-то данные.
Все три изменения написаны так, чтобы не выполняться повторно. В результате, в каком бы из промежуточных состояний не находилась база данных, при выполнении файла Changes.sql всегда будет выполнена миграция до самой последней версии.
К примеру, один из разработчиков создал на своей локальной копии БД таблицу myTable, записал изменение a) в хранящийся в общем репозитории кода файл Changes.sql, и на какое-то время забыл о нём. Теперь, если он выполнит этот файл на своей локальной БД, изменение a) будет проигнорировано, а изменения b) и c) будут применены.
Плюсы, минусы, выводы
Очень удобное выполнение миграций с любой промежуточной версии до последней - нужно всего лишь выполнить на базе данных один файл (Changes.sql);Потенциально возможны ситуации, в которых будут теряться данные, за этим придется следить. Примером может служить удаление таблицы, и затем создание другой таблицы с тем же именем. Если при удалении проверять только имя, то обе операции (удаление и создание) будут происходить каждый раз при выполнении скрипта, несмотря на то, что когда-то уже выполнялись;
Для того, чтобы изменения были идемпотентными, нужно потратить больше времени (и кода) на их написание.
Благодаря тому, что обновить базу данных до последней версии очень просто, и делать это можно вручную, этот метод показывает себя в выгодном свете в том случае, если у вас много продакшн-серверов и их нужно часто обновлять.
Метод уподобления структуры БД исходному коду
Отдельных статей, посвященных этому подходу, я, к сожалению, не нашел. Буду благодарен за ссылки на существующие статьи, если таковые имеются. UPD: В своей статье Absent рассказывает о своем опыте реализации схожего подхода при помощи самописной diff-утилиты.Основная идея этого метода отражена в заголовке: структура БД - такой же исходный код, как код PHP, C# или HTML. Следовательно, вместо того, чтобы хранить в репозитории кода файлы-миграции (с запросами, изменяющими структуру БД), нужно хранить только актуальную структуру базы данных - в декларативной форме.
Пример реализации
Для простоты примера будем считать, что в каждой ревизии репозитория всегда будет только один SQL-файл: CreateDatabase.sql. В скобках замечу, что в аналогии с исходным кодом можно пойти еще дальше и хранить структуру каждого объекта БД в отдельном файле. Также, структуру можно хранить в виде XML или других форматов, которые поддерживаются вашей СУБД.В файле CreateDatabase.sql будут храниться команды CREATE TABLE , CREATE PROCEDURE , и т.д., которые создают всю базу данных с нуля. При необходимости изменений структуры таблиц, эти изменения вносятся непосредственно в существующие DDL-запросы создания таблиц. То же касается изменений в хранимых процедурах, триггерах, и т.д.
К примеру, в текущей версии репозитория уже есть таблица myTable, и в файле CreateDatabase.sql она выглядит следующим образом:
CREATE TABLE myTable
id INT (10) NOT NULL ,
myField VARCHAR (255) NULL ,
PRIMARY KEY (id)
);
Если вам нужно добавить в эту таблицу новое поле, вы просто добавляете его в имеющийся DDL-запрос:
CREATE TABLE myTable
id INT (10) NOT NULL ,
myField VARCHAR (255) NULL ,
newfield INT(4) NOT NULL ,
PRIMARY KEY (id)
);
После этого измененный sql-файл сабмиттится в репозиторий кода.
Выполнение миграций между версиями
В этом методе процедура обновления базы данных до более новой версии не так прямолинейна, как в других методах. Поскольку для каждой версии хранится только декларативное описание структуры, для каждой миграции придется генерировать разницу в виде ALTER -, DROP - и CREATE -запросов. В этом вам помогут автоматические diff-утилиты, такие, как Schema Synchronization Tool, входящая в состав SQLyog , TOAD , доступный для многих СУБД,Современные компании нередко встают перед необходимостью миграции своих информационных систем. Однако выполнению данной процедуры должна предшествовать тщательная подготовка, так как на этом пути возникает немало препятствий.
Причин для начала перехода в новую информационную систему (ИС) может быть великое множество — это и снижение рисков, связанных с эксплуатацией устаревших платформ, и приведение информационных систем к международным стандартам, и повышение эффективности бизнес-процессов. Но независимо от того, какая задача стоит перед компанией, переход из одной ИС в другую нужно тщательно спланировать и подготовить.
Проблемы миграции
Когда речь идет о миграции транзакционных систем, таких как ERP, билинг, процессинг или АБС, переход на новую систему происходит весьма проблематично. Дело в том, что ИТ-специалистам необходимо обеспечить точную миграцию больших объемов данных, поддерживая параллельную работу старой и новой системы для проведения сверок и анализа результатов.
Например, у меня был опыт проекта в одном из крупнейших банков, где проходил переход транзакционной системы с уже не поддерживаемой платформы Informix на платформу Oracle. При этом пришлось производить тщательный анализ бизнес-процессов, многократный перенос данных из старой системы в новую и проверять соответствие результатов работы новой и старой систем с учетом длительности регламентов процессов. Именно поэтому срок миграции составил 14 мес. Иногда параллельная работа двух систем может продолжаться и более длительное время, но даже тогда, когда она ограничивается несколькими месяцами, для обеспечения работы новой ИС требуется выделение дополнительных вычислительных мощностей и значительного времени сотрудников предприятия для одновременного выполнения задач в двух системах.
От системы отдела к уровню предприятия
Нередко обновление ИС происходит в рамках глобализации и централизации. Это позволяет значительно сократить расходы на поддержку и обновление программных комплексов. Действительно, следить за единой платформой, обслуживающей всех сотрудников, значительно проще, чем поддерживать отдельные инструменты для каждого подразделения. Например, успешная миграция системы учета материально-технических ресурсов позволяет перевести несколько тысяч подразделений крупной организации на единую платформу и обеспечить серьезное сокращение издержек на ИТ. Однако следует помнить, что большая часть подготовки в данном случае приходится на согласование данных в различных форматах и представлениях, разработку новых регламентов и построение новых моделей взаимодействия сотрудников.
Еще один важный аспект — интеграционные интерфейсы с другими ИС предприятия, особенно самописными и специфическими. Проблемы, связанные с ними, могут быть не столь заметны на первом этапе, но выявляются при налаживании взаимодействия различных подразделений с общей системой. И если для старой системы такие интерфейсы уже были реализованы программно или организационно, то для новой системы их, возможно, придется разрабатывать заново.
Следует помнить, что мысли о расширении функционала системы могут прийти уже во время реализации проекта, как аппетит приходит во время еды. А это значит, что потребуется провести целый ряд дополнительных работ.
План действий
Опыт проектной деятельности по миграции систем показывает, что любой подобный проект требует тщательной подготовки и должен сопровождаться индивидуальным планом. Однако независимо от типа мигрируемых систем, программного обеспечения, объемов баз данных и пр. общая схема выглядит практически идентично.
На первом этапе необходимо провести подробный аудит, выяснив все требования, предъявляемые к режиму функционирования новой системы, опросив всех ключевых пользователей. Важно понять, о каких объемах данных, какой нагрузке идет речь, только тогда специалисты смогут предложить верную стратегию миграции.
Сами процедуры также должны быть тщательно продуманными и включать в себя такие важные элементы, как регламент доступа пользователей к системам во время миграции, процедуры отката к предыдущему состоянию в случае сбоев и порядок взаимодействия различных специалистов, участвующих в этих процессах.
После согласования с заказчиком обычно происходит составление подробного плана, который подразумевает несколько этапов, а именно: копирование данных, их верификацию, параллельную работу двух систем и полный переход на новую платформу. На мой взгляд, главное в профессионально организованной миграции систем — плавность данного процесса для пользователей, которые могут постепенно, без стресса начать работать в новой автоматизированной системе.
Впрочем, даже тщательная подготовка не всегда спасает от недооценки трудозатрат при переводе пользователей на “новые рельсы”. В этот процесс входит как проведение обучения сотрудников компании, так и их поддержка в период адаптации к новой системе.
Последнее обновление: 31.10.2015
Нередко возникает ситуация, когда модель меняется. Например, мы решили внести в нее новые свойства. Но при этом у нас уже имеется существующая база данных, в которой есть какие-то данные. И чтобы без потерь обновить базу данных ASP.NET MVC предлагает нам такой механизм как миграции. Например, у нас есть простая модель User:
Public class User { public int Id { get; set; } public string Name { get; set; } }
Соответсвенно есть контекст данных, через который мы работаем с бд:
И допустим, у нас есть вся инфраструктура для работы с этой моделью - представления, контроллеры, и у нас есть уже в базе данных несколько объектов данной модели. Но в какой-то момент мы решили изменить модельную базу приложения. Например, мы добавили еще одно поле в модель User:
Public class User { public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } }
Кроме того, мы решили добавить еще одну модель, например:
Public class Company { public int Id { get; set; } public string Name { get; set; } }
Таким образом, контекст данных у нас уже меняется следующим образом:
Public class UserContext: DbContext
{
public UserContext() :
base("DefaultConnection")
{ }
public DbSet
Мы можем добавить в представления для модели User дополнительное поле для свойства Age, можем создать контроллер и представления для новой модели, но при попытке добавить новый объект в бд, мы будем получать ошибку:
Контекст данных изменился, и теперь нам надо провести миграцию от старой схемы базы данных к новой. И первым делом найдем внизу Visual Studio окно Package Manager Console, введем в нем команду: enable-migrations и нажмем Enter:
После выполнения этой команды Visual Studio в проекте будет создана папка Migrations, в которой можно найти файл Configuration.cs . Этот файл содержит объявление одноименного класса Configuration, который устанавливает настройки конфигурации:
Namespace MigrationApp.Migrations
{
using System;
using System.Data.Entity;
using System.Data.Entity.Migrations;
using System.Linq;
internal sealed class Configuration: DbMigrationsConfiguration
В методе Seed можно проинициализировать базу данных начальными данными. Теперь нам надо создать саму миграцию. Там же в консоли Package Manager Console введем команду:
PM> Add-Migration "MigrateDB"
После этого Visual Studio автоматически сгенерирует класс миграции:
Namespace MigrationApp.Migrations { using System; using System.Data.Entity.Migrations; public partial class MigrateDB: DbMigration { public override void Up() { CreateTable("dbo.Companies", c => new { Id = c.Int(nullable: false, identity: true), Name = c.String(), }) .PrimaryKey(t => t.Id); AddColumn("dbo.Users", "Age", c => c.Int(nullable: false)); } public override void Down() { DropColumn("dbo.Users", "Age"); DropTable("dbo.Companies"); } } }
В методе Up с помощью вызова метода CreateTable создается таблица "dbo.Companies" и производится ее настройка: создание столбцов, установка ключей. И также добавляется новый столбец Age в уже имеющуюся таблицу. Метод Down удаляет столбец и таблицу на случай, если они существуют. Фактически эти методы равнозначные выражению ALTER в языке SQL, которое меняет структуру базы данных и ее таблиц.
И в завершении чтобы выполнить миграцию, применим этот класс, набрав в той же консоли команду:
PM> Update-Database
После этого, если мы посмотрим на состав базы данных, то увидим, что к ней были применены изменения в соответствии с выполненной миграцией:
Итак, миграция выполнена, и мы можем уже использовать обновленные модели и контекст данных.